
1. Introduction
In today’s digital world, client-server architecture is the invisible backbone of nearly everything we do online — from browsing websites and sending emails to using cloud-based apps and AI tools. Whether you’re watching a YouTube video, checking your bank balance through a mobile app, or chatting with ChatGPT, you’re interacting with a system built on the client-server model.
So, what is client-server architecture, and why is it so important to understand? In simple terms, it’s a method of structuring computer systems so that a client (like your browser or phone) requests information or services, and a server (a remote machine) responds with the needed data or action. This request-response cycle is how data travels across the internet quickly and reliably.
This article breaks down the fundamentals of client-server architecture in plain English, perfect for beginners. We’ll explore how it works, how client and server systems communicate, what protocols like TCP/IP and HTTP do behind the scenes, and why understanding these concepts is essential — especially if you’re learning about computer system architecture basics or diving into automation and AI workflows. Let’s demystify how the internet really works, one request at a time.
2. Understanding the Basics of Computer System Architecture
Before we dive deeper into the client-server architecture, it’s helpful to understand where it fits within the broader world of computer system architecture basics. At its core, computer system architecture refers to the structural design of a computing system — how the hardware and software components are organized to work together efficiently.
Every computing system, whether it’s a smartphone, laptop, or massive cloud server, is made up of several key layers:
- Hardware Layer: This includes physical components like the CPU, memory, hard drive, and network interfaces.
- System Software Layer: The operating system (like Windows, macOS, or Linux) manages hardware resources and provides a platform for other software.
- Application Layer: This is where user-facing applications like web browsers, email clients, or AI tools operate.
- Network Layer: This enables communication between devices through protocols such as TCP/IP.
The client-server model operates primarily in the application and network layers. The client is the part of the system that initiates communication by sending a request, and the server processes that request and sends back a response. Understanding this layered architecture helps clarify how client-server systems work and why each component plays a vital role in ensuring a smooth request-response cycle.
In essence, the client-server architecture builds on top of computer system architecture principles, using established layers and protocols to facilitate seamless communication between devices across networks.
3. What Is the Client-Server Architecture?
Client-server architecture is a foundational concept in modern computing that describes how two separate components — the client and the server — communicate over a network to complete tasks. It’s one of the most widely used models in both local and internet-based systems, powering everything from simple websites to complex enterprise applications.
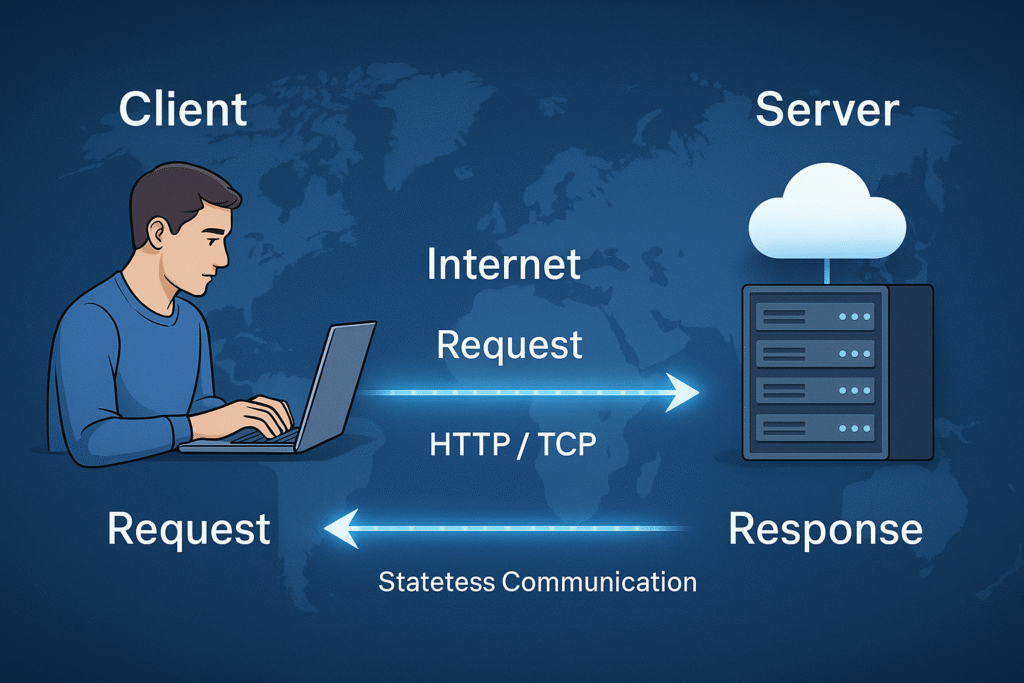
So, what is client-server architecture in simple terms? It’s a system design where the client (such as a web browser, mobile app, or desktop program) sends a request for a service or data, and the server (a powerful, often remote computer) processes that request and returns the appropriate response. This interaction is known as the request-response cycle, and it’s the heartbeat of how digital services work.
For example, when you search for something on Google, your browser acts as the client, sending a request to Google’s servers. The server then finds the relevant information and sends it back — often in milliseconds.
This client-server model works by dividing responsibilities. Clients focus on user interaction and initiating tasks, while servers handle data storage, processing, and logic. This separation makes systems more scalable, flexible, and easier to maintain.
There are many examples of client-server systems in everyday life:
- Email applications (client: your mail app, server: Gmail or Outlook server)
- Online banking systems
- Cloud storage platforms like Google Drive or Dropbox
By distributing the workload between clients and servers, client-server architecture allows multiple users to access and interact with centralized services efficiently. Understanding this model is essential not only for developers and IT professionals but also for anyone learning how computer systems work in today’s connected world.
4. How the Request-Response Cycle Works
At the heart of client-server architecture is the request-response cycle — a simple yet powerful process that enables two machines to communicate across a network. Whether you’re loading a webpage, streaming music, or asking ChatGPT a question, this cycle is happening behind the scenes in milliseconds.
Here’s how the request-response cycle works in a typical client-server system:
- Client Sends a Request:
The process begins when a client, such as a web browser or mobile app, initiates a request. For example, you type a URL into your browser and press Enter. This action creates a request for a specific webpage. - Request Travels Through the Network:
The request is packaged using TCP/IP protocols, which ensure it’s routed correctly over the internet. TCP (Transmission Control Protocol) breaks the request into smaller packets, and IP (Internet Protocol) directs them to the correct server. - Server Processes the Request:
The server — usually a remote machine running specialized software — receives the request. It could be a web server, a database server, or another type depending on the task. The server interprets the request, performs the necessary action (like fetching data), and prepares a response. - Server Sends a Response:
The response, often using the HTTP protocol, is sent back to the client. This may include HTML content, images, JSON data, or other results depending on the service. - Client Receives and Displays the Response:
Finally, the client receives the server’s response, reassembles the data (if needed), and displays it to the user. You now see the webpage, search results, or app screen you requested.
This request-response cycle is typically stateless, meaning each request is independent. This makes systems more scalable, though some applications use stateful architecture to track sessions or user interactions.
Understanding the request-response model is key to grasping how client-server systems work, especially as you explore more advanced areas like APIs, automation, and web development.
5. Client-Side Explained
In client-server architecture, the client is the part of the system that initiates communication. It’s the front-end interface that users interact with — whether it’s a web browser, mobile app, or desktop application. The client collects input from the user, sends a request to the server, and then displays the response it receives.
The client-side typically handles everything the user sees and interacts with. This includes layouts, buttons, forms, animations, and other elements designed using technologies like HTML, CSS, and JavaScript (in web applications). The client does not store or process large amounts of data locally — it depends on the server to do the heavy lifting.
Let’s take a real-world example. When you open your browser and visit an online store, your browser acts as the client. It sends a request to the website’s server to load the homepage. Once the server responds, your browser displays the content, allowing you to browse products, add items to your cart, and make a purchase.
Examples of client applications include:
- Web browsers (Chrome, Firefox, Safari)
- Email clients (Outlook, Thunderbird)
- Mobile apps (banking, social media, weather apps)
In the client-server model, the client is responsible for creating a smooth user experience. It acts as the gateway between the user and the server, ensuring requests are sent correctly and responses are displayed clearly. Understanding how the client-side functions helps you see how different devices and applications fit into the broader client-server system.
6. Server-Side Explained
In client-server architecture, the server-side is where the real processing happens. When a client sends a request—like asking for a webpage, retrieving data, or submitting a form—the server receives that request, performs the necessary actions, and returns a response.
A server is typically a powerful, remote computer (or cluster of computers) that stores data, runs applications, and handles business logic. It listens for incoming requests from clients and responds using established protocols like HTTP over TCP/IP. The goal is to deliver accurate, timely, and secure information back to the client.
There are different types of servers depending on the job:
- Web servers (like Apache or Nginx) deliver web pages and static content.
- Application servers run backend logic, such as handling user logins or processing payments.
- Database servers store and retrieve structured data for apps and websites.
Let’s say you’re logging into your email. Your device (the client) sends your login credentials to the server-side, which verifies your information against its database. If everything checks out, it sends back a successful login response and displays your inbox.
The server-side is also responsible for handling security, authentication, and storing session data in stateful systems. In stateless systems, each request is treated independently.
Understanding the server’s role in the client-server model is essential to knowing how web apps, cloud services, and even AI-powered tools operate behind the scenes. It’s the engine room of any digital service — quiet but critical.
7. Stateless vs Stateful Architecture
When learning about client-server architecture, one key concept to understand is the difference between stateless and stateful architecture. These terms describe how servers handle client requests over time — and they play a big role in the performance and design of client-server systems.
In a stateless architecture, each request-response cycle is completely independent. The server does not remember anything about the client between requests. Most web applications that use HTTP follow a stateless model by default. For example, when you refresh a webpage, the server processes it like a brand-new request, unaware of what you did before.
Stateless systems are:
- Easier to scale
- More reliable
- Simpler to manage
However, they often require workarounds like cookies or tokens to maintain user sessions (e.g., keeping you logged in).
On the other hand, stateful architecture maintains context between requests. This means the server stores information (or “state”) about previous interactions with the client. For instance, when you add items to your shopping cart on an e-commerce site and return later, the server remembers your cart — that’s a stateful interaction.
Stateful systems are:
- Great for tracking sessions or personalized experiences
- More resource-intensive
- Harder to scale at large volumes
Choosing between stateless and stateful architecture depends on the application’s needs. Understanding both is crucial for building efficient, scalable client-server systems that deliver the right experience to users.
8. Client-Server vs Peer-to-Peer (P2P)
While client-server architecture is the most common model used in modern computing, it’s not the only one. Another popular design is peer-to-peer (P2P) architecture. Understanding the difference between the two helps you see how different systems are structured based on their goals.
In the client-server model, there is a clear distinction: the client requests services, and the server provides them. This centralized approach allows for better control, security, and scalability. It’s ideal for websites, cloud apps, and most business software systems.
In contrast, peer-to-peer architecture allows each device (or “peer”) in the network to act as both a client and a server. Instead of relying on a central server, peers share resources and data directly with each other. A well-known example is file-sharing platforms like BitTorrent, where users download and upload files simultaneously.
Key differences:
- Client-server systems are centralized; P2P systems are decentralized.
- Client-server offers better control and security; P2P excels in redundancy and scalability.
- Client-server is used in web apps, online banking, and cloud tools; P2P suits file sharing, blockchain, and collaborative platforms.
While each has its advantages, most modern systems rely on client-server architecture for its simplicity, reliability, and ease of management.
9. Security in Client-Server Systems
Security is a critical part of any client-server architecture, especially since most modern applications involve transmitting sensitive data—like passwords, personal information, or payment details—over the internet. Without proper protection, both the client and server sides can become vulnerable to cyberattacks.
In a client-server system, most data is exchanged using the request-response cycle, often through HTTP or HTTPS protocols. To secure this communication, HTTPS (Hypertext Transfer Protocol Secure) encrypts data using SSL/TLS, making it unreadable to anyone who might intercept it during transmission. This is why secure websites display a padlock icon in the browser.
Authentication and authorization are also crucial. Before granting access to resources, the server must verify the identity of the client (authentication) and check if the client has permission to perform a specific action (authorization). This is usually managed through login systems, session tokens, or API keys.
Common security measures in client-server systems include:
- SSL/TLS encryption for secure communication
- Firewalls to block unauthorized access
- Rate limiting to prevent abuse of server resources
- Input validation to avoid injection attacks
Despite being a reliable model, the client-server architecture is not immune to threats like man-in-the-middle attacks, data breaches, or denial-of-service (DoS) attacks. That’s why applying best practices in both development and server management is essential to keeping client-server systems secure and trustworthy.
10. Modern Uses and Future Trends
The client-server architecture continues to evolve and adapt to meet the demands of modern technology. Today, it serves as the backbone of countless services — from cloud platforms like Google Cloud and AWS to AI-powered applications, online gaming, and mobile banking.
One major trend is the rise of cloud computing, where clients connect to powerful, scalable servers hosted in remote data centers. This setup enables services like Google Drive, Zoom, and ChatGPT to deliver real-time experiences across devices. Another innovation built on the client-server model is the use of microservices, where applications are split into smaller, independently running services — each acting as its own mini-server.
Serverless computing is also reshaping how developers use the server-side. In this model, developers write functions that run on demand, and cloud providers manage the infrastructure behind the scenes. Although the server is still there, the complexity of managing it is hidden from the developer.
Looking forward, the client-server model will continue to adapt through AI integration, edge computing, and real-time data processing. Despite new trends, the fundamental principles of client-server systems — request, process, respond — remain core to how modern digital experiences are built and scaled efficiently.
You can also read AI Automation Tools You Should Know (No-Code, Low-Code, and Dev Tools)
11. Conclusion
Understanding client-server architecture is essential for anyone looking to grasp how modern computer systems and internet services work. Whether you’re browsing a website, using an app, or accessing cloud storage, you’re interacting with a client-server model that handles requests and delivers responses in real time.
In this article, we explored the fundamentals of the client-server architecture, how the request-response cycle functions, and the distinct roles of clients and servers. We also looked at concepts like stateless vs stateful systems, compared client-server systems to peer-to-peer (P2P) networks, and examined the importance of security in these interactions.
As digital technologies continue to grow, this architecture remains at the core of everything from cloud computing to AI-powered automation. By understanding how client-server systems work, you’re better equipped to explore advanced tech topics like APIs, workflow automation, and data-driven applications.
Whether you’re a beginner or building your first automation project, this foundational knowledge is a valuable step toward becoming more tech-savvy. Keep exploring, and you’ll soon see how deeply this architecture shapes the digital world around us.
12. FAQs
What is a client in client-server architecture?
A client is the part of a client-server system that initiates communication by sending a request to the server. It’s typically a web browser, mobile app, or software application that interacts with users and displays server responses.
What is a request-response model in computing?
The request-response model is a communication pattern where a client sends a request to the server, and the server returns a response. This cycle is the foundation of how data is exchanged in client-server architecture, especially over the internet.
Is HTTP a client-server protocol?
Yes, HTTP (Hypertext Transfer Protocol) is a stateless protocol used in client-server communication. It enables the transfer of web content between a client (like a browser) and a server.
What is the difference between client-server and peer-to-peer (P2P)?
In client-server architecture, roles are fixed: clients request, and servers respond. In peer-to-peer (P2P) systems, each device can act as both a client and a server, sharing resources directly without central coordination.
Next, read What Is AI Automation? A Deep Dive Into How It Works in 2025

